

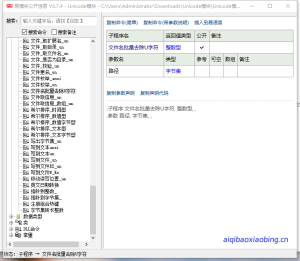
众所周知易语言针对Unicode编码的内容是很难处理的。
这个模块有一个好用的功能就是
文件名批量去除U字符
这个功能在处理读写的时候就很方便,提前吧带有Unicode编码的文件路径格式处理一下
后面在获取就正常的。
不知道有没有,易友碰到过这种类似的情况,个人觉得这么模块挺好用的,分享给大家。

写法需要把路径转换成字节集的形式就可以了,写一个计次循环。
免费资源
© 版权声明
THE END
众所周知易语言针对Unicode编码的内容是很难处理的。
这个模块有一个好用的功能就是
文件名批量去除U字符
这个功能在处理读写的时候就很方便,提前吧带有Unicode编码的文件路径格式处理一下
后面在获取就正常的。
不知道有没有,易友碰到过这种类似的情况,个人觉得这么模块挺好用的,分享给大家。
写法需要把路径转换成字节集的形式就可以了,写一个计次循环。














暂无评论内容